Over the last four years, my former team at Sun has been focussed on cloud computing, its value to Sun's potential customers, and the most effective ways to make its value accessible to developers. A significant artifact that research was Project Caroline, which was demonstrated in April 2008 at the SunLabs Open House.
Here is a pointed to that presentation.
It begins with my introduction and motivation for the project. At 5:30, John McClain gives a demonstration of the use of Project Caroline to create an Internet service, creating a Facebook application. At 34:00, Bob Scheifler gives a developer oriented view of the resources available in the Project Caroline platform and how those resources are programmatically controlled. At 1:06:00, Vinod Johnson demonstrates how the Project Caroline architecture and API's facilitate the creation and deployment of horizontally scaled applications that dynamically adjust their resource utilization. This is done using a early version of the Glassfish 3.0 application server that has been modified to work with Project Caroline. Finally, at 1:33:30, John McClain returns to summarize the demos and the answer a few questions.
While the project is no longer active at Sun, the Project Caroline web site is still running, where you can find additional technical discussions and through which can download all of the source code for Project Caroline. It's worth noting that that web site is a Drupal managed web site that itself is running on Project Caroline!
Thursday, March 26, 2009
Wednesday, March 4, 2009
The Data Center Layer Cake
In thinking through our customer's needs in cloud computing/utility computing or whatever else you want to call it, we've found the attached diagram, which maps the technologies in a data center to be very useful. All data centers contain three different types of technologies: computing, storage, and communications. Depending on the role of the data center the ratio of investments in these three areas will vary, but all three areas need some form of investment. These three areas are represented by the three columns in the diagram.
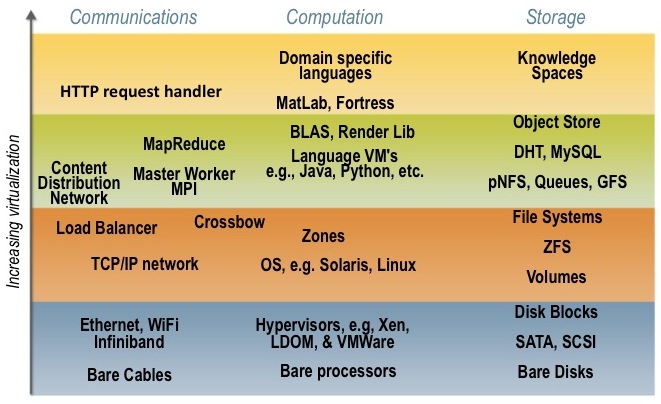
The vertical axis corresponds to the level of virtualization or abstraction at which that technology area is expressed. For instance, computation could be expressed as specific hardware (a server or processor), as a virtualized processor using a hypervisor like Xen, VMWare, or LDOMs, as a process in supported by an operating system, a language level VM (like the Java VM), etc. As you can see, the computing community has built a rich array of technology abstractions over the years, of which only a small fraction are illustrated.
The purpose of these virtualization or abstraction points is to provide clean, well defined boundaries between the developers and those that create and manage the IT infrastructure for the applications and services created by the developers. While all developers claim to need complete control of the resources in the data center, and all data center operators claim complete control over the software deployed and managed in the data center, in reality a boundary is usually defined between the developer domain and the domains of the data center operator.
On the following diagram we have overlaid rough charactures of some of these boundaries. Higher the line is, the room the DC operator has to innovate (e.g., in choosing types of disks, networking, or processors), and smaller the developer's job in actually building the desired service or application.
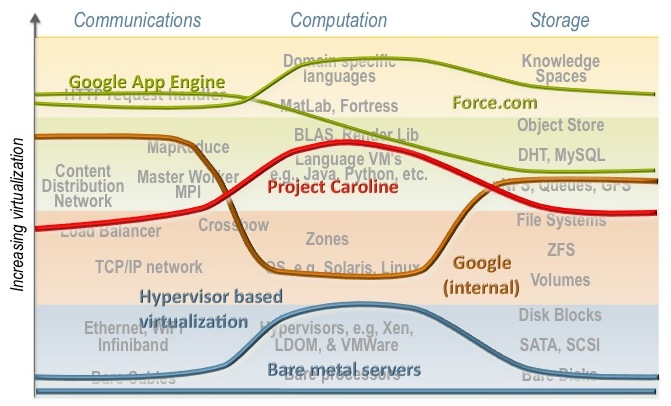
At the bottom of the diagram we have the traditional data center, where the developer spec's the hardware and the DC operator merely cables it up. Obviously, this gives the developers the most flexibility to achieve "maximum" performance; but it makes the DC operators job a nightmare. The next line up corresponds, more or less, to the early days of EC2 or VMWare where developers could launch VM's, but these VM's talked to virtual NIC's and virtual SAS disks. It is incredibly challenging to connect a distributed file system or content distribution network to a VM which doesn't even have an OS attached.
The brown line corresponds to what we surmise to be the internal platform used by Google developers. For compute, they develop to the Linux platform; for storage distributed file systems like GFS and distributed structured storage like Bigtable and Chubby are used. I suspect that most developers don't really interact with TCP/IP but instead use distributed control structures like MapReduce.
My team's Project Caroline is represented by the red line. We used language specific processes as the compute abstraction, completely hiding the underlining operating system used on the servers. This allowed us to leave the instruction set choice to the data center operator.
The green lines correspond to two even high level platforms, Google App Engine and Force.com. Note that these platforms make it very easy to build specific types of applications and services, but not all types. Building a general purpose search engine on Force.com or Google App Engine would be quite difficult, while straightforward with Project Caroline or the internal Google platform.
The key question for developers is, Which line to choose? If you are building a highly scalable search/advertising engine then both the green and blue lines would lead to costly solutions, either in the development, management, or both. But if you are building a CRM application then Force.com is the obvious choice. If you have lots of legacy software that requires specific hardware the the hypervisor approach makes the most sense. However, if you are building a multiplayer online game, then none these lines might be optimal. Instead, the line corresponding to Project Darkstar would probably be the best choice.
Regardless, the definition of this line is usually a good place to begin in a large scale project. It is the basic contract between the developers and the IT infrastructure managers.
The above discussion oversimplifies a number of issues to make the general principles clearer. Many business issues like partner relationships, billing, needs for specialized hardware, etc. impinge on the simplicity of this "layer cake" model.
Also, note that Amazon's EC2 offering hasn't been static, but has grown a number of higher level abstractions (elastic storage, content distribution, queues, etc.) that allow the developer to choose different lines than the blue hypervisor one and still use AWS. We find the rapid growth and use of these new technologies encouraging as they flesh out the viable virtualization points in the layer cake.
The vertical axis corresponds to the level of virtualization or abstraction at which that technology area is expressed. For instance, computation could be expressed as specific hardware (a server or processor), as a virtualized processor using a hypervisor like Xen, VMWare, or LDOMs, as a process in supported by an operating system, a language level VM (like the Java VM), etc. As you can see, the computing community has built a rich array of technology abstractions over the years, of which only a small fraction are illustrated.
The purpose of these virtualization or abstraction points is to provide clean, well defined boundaries between the developers and those that create and manage the IT infrastructure for the applications and services created by the developers. While all developers claim to need complete control of the resources in the data center, and all data center operators claim complete control over the software deployed and managed in the data center, in reality a boundary is usually defined between the developer domain and the domains of the data center operator.
On the following diagram we have overlaid rough charactures of some of these boundaries. Higher the line is, the room the DC operator has to innovate (e.g., in choosing types of disks, networking, or processors), and smaller the developer's job in actually building the desired service or application.
At the bottom of the diagram we have the traditional data center, where the developer spec's the hardware and the DC operator merely cables it up. Obviously, this gives the developers the most flexibility to achieve "maximum" performance; but it makes the DC operators job a nightmare. The next line up corresponds, more or less, to the early days of EC2 or VMWare where developers could launch VM's, but these VM's talked to virtual NIC's and virtual SAS disks. It is incredibly challenging to connect a distributed file system or content distribution network to a VM which doesn't even have an OS attached.
The brown line corresponds to what we surmise to be the internal platform used by Google developers. For compute, they develop to the Linux platform; for storage distributed file systems like GFS and distributed structured storage like Bigtable and Chubby are used. I suspect that most developers don't really interact with TCP/IP but instead use distributed control structures like MapReduce.
My team's Project Caroline is represented by the red line. We used language specific processes as the compute abstraction, completely hiding the underlining operating system used on the servers. This allowed us to leave the instruction set choice to the data center operator.
The green lines correspond to two even high level platforms, Google App Engine and Force.com. Note that these platforms make it very easy to build specific types of applications and services, but not all types. Building a general purpose search engine on Force.com or Google App Engine would be quite difficult, while straightforward with Project Caroline or the internal Google platform.
The key question for developers is, Which line to choose? If you are building a highly scalable search/advertising engine then both the green and blue lines would lead to costly solutions, either in the development, management, or both. But if you are building a CRM application then Force.com is the obvious choice. If you have lots of legacy software that requires specific hardware the the hypervisor approach makes the most sense. However, if you are building a multiplayer online game, then none these lines might be optimal. Instead, the line corresponding to Project Darkstar would probably be the best choice.
Regardless, the definition of this line is usually a good place to begin in a large scale project. It is the basic contract between the developers and the IT infrastructure managers.
Addendum:
The above discussion oversimplifies a number of issues to make the general principles clearer. Many business issues like partner relationships, billing, needs for specialized hardware, etc. impinge on the simplicity of this "layer cake" model.
Also, note that Amazon's EC2 offering hasn't been static, but has grown a number of higher level abstractions (elastic storage, content distribution, queues, etc.) that allow the developer to choose different lines than the blue hypervisor one and still use AWS. We find the rapid growth and use of these new technologies encouraging as they flesh out the viable virtualization points in the layer cake.
Wednesday, February 25, 2009
Cloud Computing Value Propositions
To cut through all the hype around cloud computing, I think you need to focus on what value is ultimately delivered to the developer who builds his or her systems on "Cloud infrastructures." I say the developer here rather than the end user because the end user really cares more about their applications and services, not how those services are implemented.
In a recent paper published by researchers from the RADLab at UC Berkeley, Above the Clouds: A Berkeley View of Cloud Computing three new hardware aspects of Cloud Computing are suggested:
But these are all just variants of "capital expenditure (CAPEX) to operating costs (OPEX) conversion." And in other contexts, it goes by the slightly jaundiced term outsourcing. We've been doing this for years in IT, but the refined techniques developed by Amazon, Google, and others has made finer grain outsourcing practical.
While these benefits are valuable and lower the barrier to entry for many startups and small organizations, it shares the same pitfalls of outsourced manufacturing or design.
I believe there is more value to Computing Computing than just new way to outsource. Cloud Computing delivers a far more unique value of enabling business agility.
Those who have benefited from Cloud Computing, like Google and Salesforce.com have done so because their developers have a much richer platform to work with than is traditional. They don't need to configure operating systems or databases, they don't need to port new packages to their environment and painfully identify conflicting interdependencies. Instead, they have a relatively comprehensive platform to develop to, which provides distributed data store, data mining, load balancing, etc. without any development or configuration on their part.
It is this rich platform, which spans computing, storage, and communications, that allows Google to rapidly respond to business changes and market sentiment, and run more agilely than their competitors.
The original EC2/S3 offering effectively delivered on the outsourcing business value, but what has made Amazon Web Services compelling today is the rich platform that an AWS developer has at their disposal: load balancing from Right Scale, the Hadoop infrastructure from Cloudera, Amazon's content distribution network, etc. So, I believe that a real challenge to the success of Cloud Computoing is determining the characteristics of a "platform", that provides the greatest value for Cloud Computing developers. Too high a level of abstraction, e.g., Force.com narrows the application range.
Too low a level, and you are just outsourcing your IT hardware.
In a recent paper published by researchers from the RADLab at UC Berkeley, Above the Clouds: A Berkeley View of Cloud Computing three new hardware aspects of Cloud Computing are suggested:
- The illusion of infinite computing resources available on demand
- The elimination of an up-front commitment by Cloud users.
- The ability to pay for use of computer resources as needed,
But these are all just variants of "capital expenditure (CAPEX) to operating costs (OPEX) conversion." And in other contexts, it goes by the slightly jaundiced term outsourcing. We've been doing this for years in IT, but the refined techniques developed by Amazon, Google, and others has made finer grain outsourcing practical.
While these benefits are valuable and lower the barrier to entry for many startups and small organizations, it shares the same pitfalls of outsourced manufacturing or design.
I believe there is more value to Computing Computing than just new way to outsource. Cloud Computing delivers a far more unique value of enabling business agility.
Those who have benefited from Cloud Computing, like Google and Salesforce.com have done so because their developers have a much richer platform to work with than is traditional. They don't need to configure operating systems or databases, they don't need to port new packages to their environment and painfully identify conflicting interdependencies. Instead, they have a relatively comprehensive platform to develop to, which provides distributed data store, data mining, load balancing, etc. without any development or configuration on their part.
It is this rich platform, which spans computing, storage, and communications, that allows Google to rapidly respond to business changes and market sentiment, and run more agilely than their competitors.
The original EC2/S3 offering effectively delivered on the outsourcing business value, but what has made Amazon Web Services compelling today is the rich platform that an AWS developer has at their disposal: load balancing from Right Scale, the Hadoop infrastructure from Cloudera, Amazon's content distribution network, etc. So, I believe that a real challenge to the success of Cloud Computoing is determining the characteristics of a "platform", that provides the greatest value for Cloud Computing developers. Too high a level of abstraction, e.g., Force.com narrows the application range.
Too low a level, and you are just outsourcing your IT hardware.
Friday, January 30, 2009
First posting ... on Cloud Computing
I've just started this blog, and haven't had time to write out a really useful posting. But I thought I'd start with a few comments about Cloud Computing. At this point, I think the most important issue is understanding what the value of Cloud Computing is to the end user, the person who ultimately pays for it.
My old boss, Shane Robison just said on an interview on CNBC that Cloud Computing is a new business model [for information based activities]. While is certainly true, what about cloud computing enables this new business model? I believe there are two features that are game changers.
First, cloud computing, and the whole industrial move to towards delivering services, enables business to move their overall IT expenses from the capital expense line to the operating expense line. That is, rent computing and communications, don't buy it. This is certainly the direction we should be moving and we have been doing this for many years (out sourcing of IT is just one example). This, conversion of CAPEX to OPEX is hugely important, but it is really just the tip of the iceberg.
The second value of cloud computing is that it can enable great business agility, either by allowing short, burst uses of large amounts of IT infrastructure, or by encouraging and supporting very rapid creating, modification, and deployment of new services. This agility allows companies to respond to market changes much more rapidly and deliver their information based products in ways that are more appealing to their customers.
This new found business agility, perhaps best demonstrated by Google and Facebook, is what makes competing with these companies so challenging. A major goal of wide spread cloud computing should be to make this type of business agility available to all. This is a new business model.
My old boss, Shane Robison just said on an interview on CNBC that Cloud Computing is a new business model [for information based activities]. While is certainly true, what about cloud computing enables this new business model? I believe there are two features that are game changers.
First, cloud computing, and the whole industrial move to towards delivering services, enables business to move their overall IT expenses from the capital expense line to the operating expense line. That is, rent computing and communications, don't buy it. This is certainly the direction we should be moving and we have been doing this for many years (out sourcing of IT is just one example). This, conversion of CAPEX to OPEX is hugely important, but it is really just the tip of the iceberg.
The second value of cloud computing is that it can enable great business agility, either by allowing short, burst uses of large amounts of IT infrastructure, or by encouraging and supporting very rapid creating, modification, and deployment of new services. This agility allows companies to respond to market changes much more rapidly and deliver their information based products in ways that are more appealing to their customers.
This new found business agility, perhaps best demonstrated by Google and Facebook, is what makes competing with these companies so challenging. A major goal of wide spread cloud computing should be to make this type of business agility available to all. This is a new business model.
Subscribe to:
Posts (Atom)