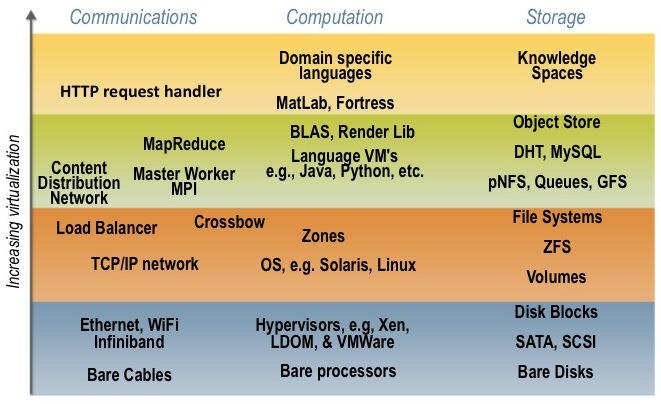
The vertical axis corresponds to the level of virtualization or abstraction at which that technology area is expressed. For instance, computation could be expressed as specific hardware (a server or processor), as a virtualized processor using a hypervisor like Xen, VMWare, or LDOMs, as a process in supported by an operating system, a language level VM (like the Java VM), etc. As you can see, the computing community has built a rich array of technology abstractions over the years, of which only a small fraction are illustrated.
The purpose of these virtualization or abstraction points is to provide clean, well defined boundaries between the developers and those that create and manage the IT infrastructure for the applications and services created by the developers. While all developers claim to need complete control of the resources in the data center, and all data center operators claim complete control over the software deployed and managed in the data center, in reality a boundary is usually defined between the developer domain and the domains of the data center operator.
On the following diagram we have overlaid rough charactures of some of these boundaries. Higher the line is, the room the DC operator has to innovate (e.g., in choosing types of disks, networking, or processors), and smaller the developer's job in actually building the desired service or application.
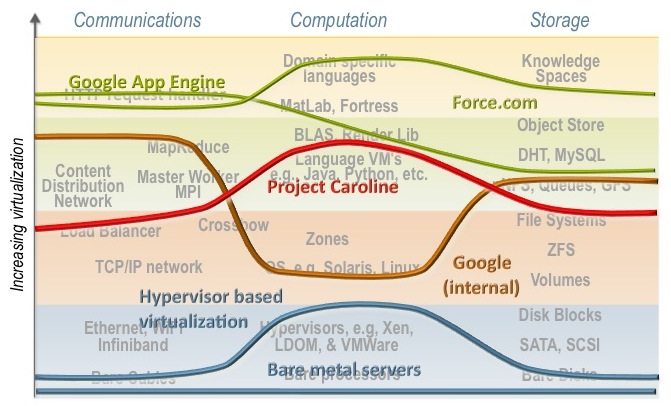
At the bottom of the diagram we have the traditional data center, where the developer spec's the hardware and the DC operator merely cables it up. Obviously, this gives the developers the most flexibility to achieve "maximum" performance; but it makes the DC operators job a nightmare. The next line up corresponds, more or less, to the early days of EC2 or VMWare where developers could launch VM's, but these VM's talked to virtual NIC's and virtual SAS disks. It is incredibly challenging to connect a distributed file system or content distribution network to a VM which doesn't even have an OS attached.
The brown line corresponds to what we surmise to be the internal platform used by Google developers. For compute, they develop to the Linux platform; for storage distributed file systems like GFS and distributed structured storage like Bigtable and Chubby are used. I suspect that most developers don't really interact with TCP/IP but instead use distributed control structures like MapReduce.
My team's Project Caroline is represented by the red line. We used language specific processes as the compute abstraction, completely hiding the underlining operating system used on the servers. This allowed us to leave the instruction set choice to the data center operator.
The green lines correspond to two even high level platforms, Google App Engine and Force.com. Note that these platforms make it very easy to build specific types of applications and services, but not all types. Building a general purpose search engine on Force.com or Google App Engine would be quite difficult, while straightforward with Project Caroline or the internal Google platform.
The key question for developers is, Which line to choose? If you are building a highly scalable search/advertising engine then both the green and blue lines would lead to costly solutions, either in the development, management, or both. But if you are building a CRM application then Force.com is the obvious choice. If you have lots of legacy software that requires specific hardware the the hypervisor approach makes the most sense. However, if you are building a multiplayer online game, then none these lines might be optimal. Instead, the line corresponding to Project Darkstar would probably be the best choice.
Regardless, the definition of this line is usually a good place to begin in a large scale project. It is the basic contract between the developers and the IT infrastructure managers.
Addendum:
The above discussion oversimplifies a number of issues to make the general principles clearer. Many business issues like partner relationships, billing, needs for specialized hardware, etc. impinge on the simplicity of this "layer cake" model.
Also, note that Amazon's EC2 offering hasn't been static, but has grown a number of higher level abstractions (elastic storage, content distribution, queues, etc.) that allow the developer to choose different lines than the blue hypervisor one and still use AWS. We find the rapid growth and use of these new technologies encouraging as they flesh out the viable virtualization points in the layer cake.
No comments:
Post a Comment